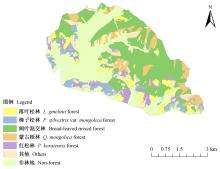
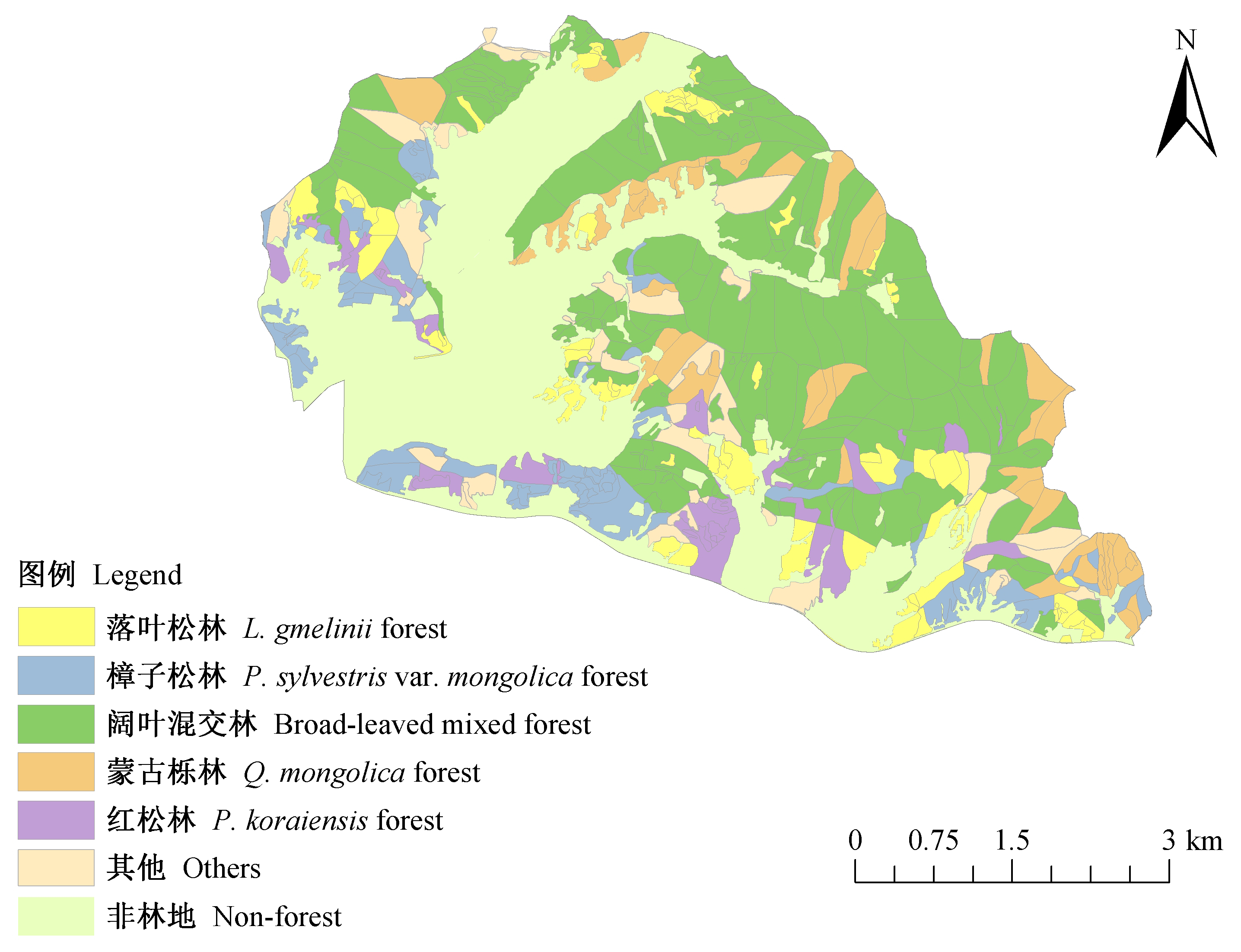
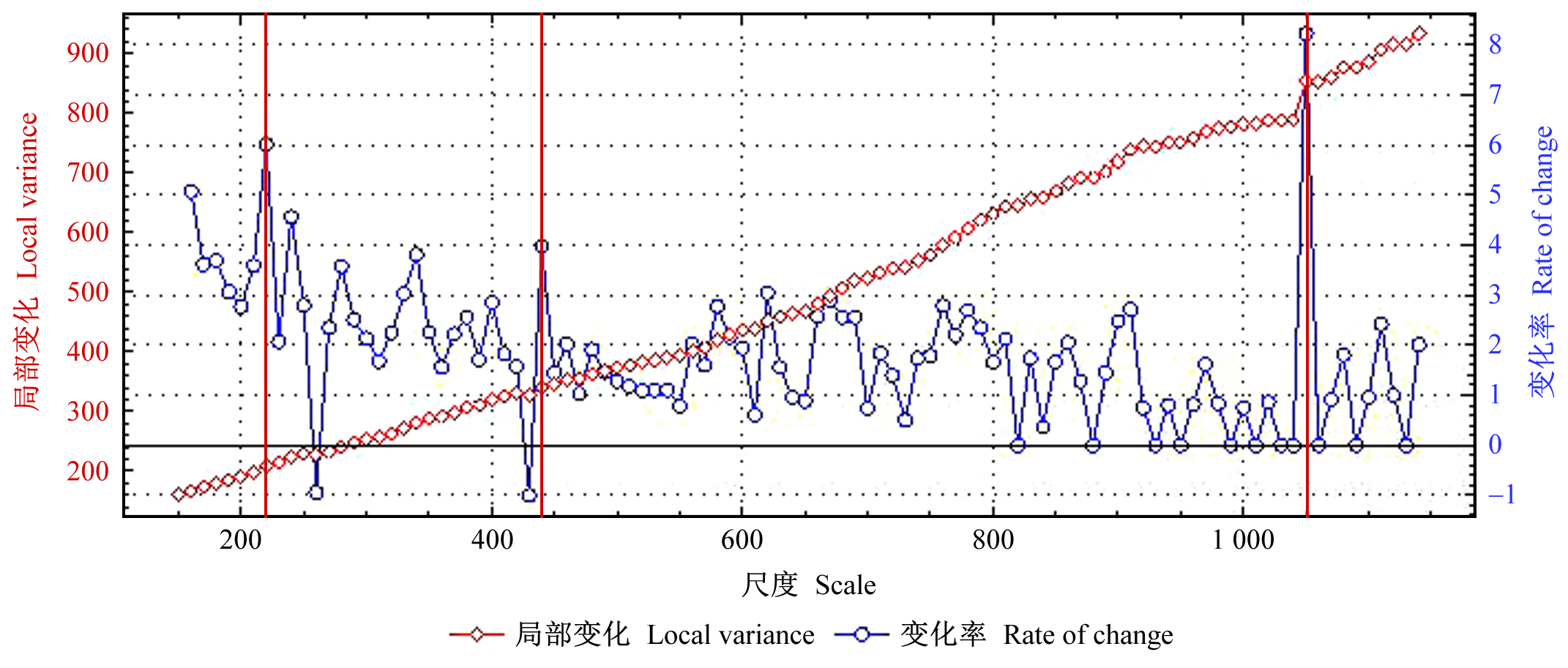
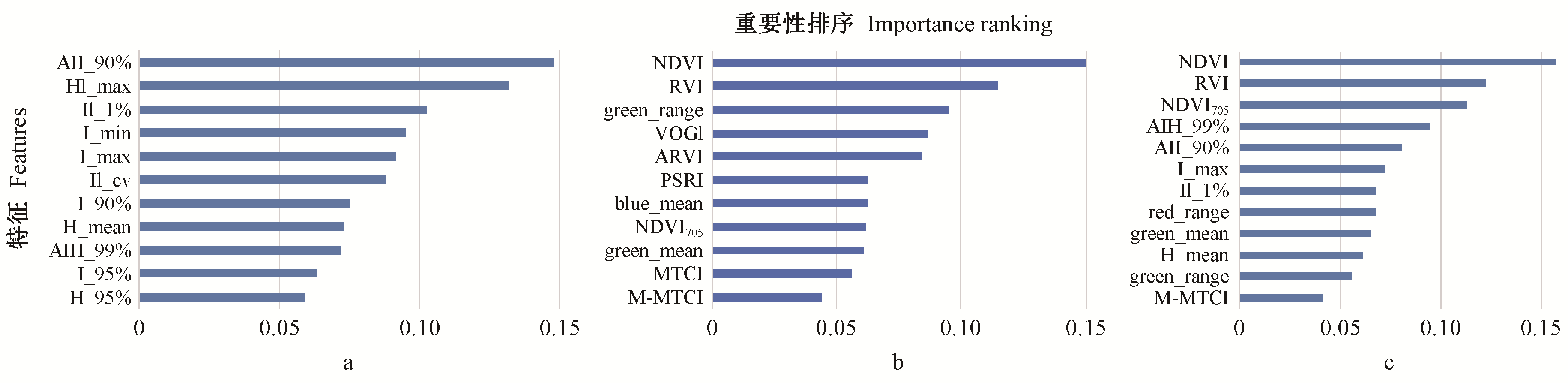
|
陈永健. 2014. 半监督支持向量机分类方法研究. 西安: 陕西师范大学硕士学位论文.
|
|
Chen Y J. 2014. Research on classification methods of semi-supervised support vector machines. Xi'an: MS thesis of Shaanxi Normal University. [in Chinese]
|
|
丁壮, 姚余君, 宋日清. 帽儿山实验林场老山地区森林资源的历史变迁. 东北林业大学学报, 2006, 34 (3): 87- 89.
doi: 10.3969/j.issn.1000-5382.2006.03.035
|
|
Ding Z , Yao Y J , Song R Q . Historical changes of forest resources in Laoshan area of Mao'ershan experimental forest farm. Journal of Northeast Forestry University, 2006, 34 (3): 87- 89.
doi: 10.3969/j.issn.1000-5382.2006.03.035
|
|
董恒, 孟庆野, 王金梁, 等. 一种改进的叶绿素提取植被指数. 红外与毫米波学报, 2012, 31 (4): 336- 341.
|
|
Dong H , Meng Q Y , Wang J L , et al. An improved chlorophyll extraction vegetation index. Journal of Infrared and Millimeter Wave, 2012, 31 (4): 336- 341.
|
|
樊雪. 2016. 机载PHI高光谱数据的森林类型精细识别方法研究. 北京: 中国林业科学研究院硕士学位论文.
|
|
Fan X. 2016. Research on fine recognition method of forest types based on airborne PHI hyperspectral data. Beijing: MS thesis of Chinese Academy of Forestry. [in Chinese]
|
|
皋厦, 申鑫, 代劲松, 等. 结合LiDAR单木分割和高光谱特征提取的城市森林树种分类. 遥感技术与应用, 2018, 33 (6): 1073- 1083.
|
|
Gao S , Shen X , Dai J S , et al. Classification of urban forest tree species combined with LiDAR single tree segmentation and hyperspectral feature extraction. Remote Sensing Technology and Application, 2018, 33 (6): 1073- 1083.
|
|
黄衍, 查伟雄. 随机森林与支持向量机分类性能比较. 软件, 2012, 33 (6): 107- 110.
doi: 10.3969/j.issn.1003-6970.2012.06.038
|
|
Huang Y , Zha W X . Comparison of classification performance between random forests and support vector machine. Software, 2012, 33 (6): 107- 110.
doi: 10.3969/j.issn.1003-6970.2012.06.038
|
|
李波. 2017. 机载激光点云和高光谱影像融合的城市地物分类研究. 武汉: 武汉大学硕士学位论文.
|
|
Li B. 2017. Classification of urban ground objects based on fusion of airborne laser point clouds and hyperspectral images. Wuhan: MS thesis of Wuhan University. [in Chinese]
|
|
李明泽, 付瑜, 于颖, 等. 基于多时相SAR数据和SPOT数据的盘古林场林分类型识别. 植物研究, 2016, 36 (4): 613- 619, 626.
|
|
Li M Z , Fu Y , Yu Y , et al. Stand type identification of Pangu forest farm based on multi-temporal SAR data and SPOT data. Plant Research, 2016, 36 (4): 613- 619, 626.
|
|
刘丽娟, 庞勇, 范文义, 等. 机载LiDAR和高光谱融合实现温带天然林树种识别. 遥感学报, 2013, 17 (3): 679- 695.
|
|
Liu L J , Pang Y , Fan W Y , et al. Airborne LiDAR and hyperspectral fusion for tree species identification in temperate natural forests. Journal of Remote Sensing, 2013, 17 (3): 679- 695.
|
|
刘舒, 姜琦刚, 马玥, 等. 基于多目标遗传随机森林特征选择的面向对象湿地分类. 农业机械学报, 2017, 48 (1): 119- 127.
|
|
Liu S , Jiang Q G , Ma Y , et al. Object-oriented wetland classification based on multi-objective genetic random forest feature selection. Journal of Agricultural Machinery, 2017, 48 (1): 119- 127.
|
|
刘思涵, 尚夏明, 马婷. 基于随机森林特征选择的森林类型分类. 北京测绘, 2019, 33 (12): 1518- 1522.
|
|
Liu S H , Shang X M , Ma T . Classification of forest types based on random forest feature selection. Beijing Mapping, 2019, 33 (12): 1518- 1522.
|
|
刘毅, 杜培军, 郑辉, 等. 基于随机森林的国产小卫星遥感影像分类研究. 测绘科学, 2012, 37 (4): 194- 196.
|
|
Liu Y , Du P J , Zheng H , et al. Classification of domestic small satellite remote sensing images based on random forests. Surveying and Mapping Science, 2012, 37 (4): 194- 196.
|
|
刘怡君, 庞勇, 廖声熙, 等. 机载LiDAR和高光谱融合实现普洱山区树种分类. 林业科学研究, 2016, 29 (3): 407- 412.
doi: 10.3969/j.issn.1001-1498.2016.03.015
|
|
Liu Y J , Pang Y , Liao S X , et al. Airborne LiDAR and hyperspectral fusion to realize tree species classification in Pu'er mountain area. Forest Research, 2016, 29 (3): 407- 412.
doi: 10.3969/j.issn.1001-1498.2016.03.015
|
|
鲁续坤. 2018. 机载LiDAR和高光谱数据的树种分类及三维显示. 成都: 电子科技大学硕士学位论文.
|
|
Lu X K. 2018. Tree species classification and 3D display of airborne LiDAR and hyperspectral data. Chengdu: MS thesis of University of Electronic Science and Technology. [in Chinese]
|
|
毛学刚, 魏晶昱. 基于多源遥感数据的面向对象林分类型识别. 应用生态学报, 2017, 28 (11): 3711- 3719.
|
|
Mao X G , Wei J Y . Object-oriented stand type identification based on multi-source remote sensing data. Journal of Applied Ecology, 2017, 28 (11): 3711- 3719.
|
|
王婷. 2017. 高光谱遥感图像数据降维和分类算法研究. 银川: 北方民族大学硕士学位论文.
|
|
Wang T. 2017. Research on dimension reduction and classification algorithms for hyperspectral remote sensing image data. Yinchuan: MS thesis of Northern University for Nationalities. [in Chinese]
|
|
温小乐, 钟奥, 胡秀娟. 基于随机森林特征选择的城市绿化乔木树种分类. 地球信息科学学报, 2018, 20 (12): 1777- 1786.
doi: 10.12082/dqxxkx.2018.180310
|
|
Wen X L , Zhong A , Hu X J . Classification of urban greening tree species based on random forest feature selection. Journal of Geoscience, 2018, 20 (12): 1777- 1786.
doi: 10.12082/dqxxkx.2018.180310
|
|
谢珠利. 2019. 基于多源高分辨率遥感数据的人工林树种分类研究. 杭州: 浙江农林大学硕士学位论文.
|
|
Xie Z L. 2019. Classification of plantation tree species based on multi-source and high-resolution remote sensing data. Hangzhou: MS thesis of Zhejiang Agriculture and Forestry University. [in Chinese]
|
|
熊艳, 高仁强, 徐战亚. 机载LiDAR点云数据降维与分类的随机森林方法. 测绘学报, 2018, 47 (4): 508- 518.
|
|
Xiong Y , Gao R Q , Xu Z Y . Random forest method for dimension reduction and classification of airborne LiDAR point cloud data. Acta Surveying and Mapping Sinica, 2018, 47 (4): 508- 518.
|
|
颜春燕, 牛铮, 王纪华, 等. 光谱指数用于叶绿素含量提取的评价及一种改进的农作物冠层叶绿素含量提取模型. 遥感学报, 2005, 9 (6): 742- 750.
|
|
Yan C Y , Niu Z , Wang J H , et al. Spectral index for evaluation of chlorophyll content extraction and an improved model for extraction of chlorophyll content in crop canopy. Journal of Remote Sensing, 2005, 9 (6): 742- 750.
|
|
杨珺雯, 张锦水, 朱秀芳, 等. 随机森林在高光谱遥感数据中降维与分类的应用. 北京师范大学学报: 自然科学版, 2015, 51 (S1): 82- 88.
|
|
Yang J W , Zhang J S , Zhu X F , et al. Application of random forests in dimension reduction and classification of hyperspectral remote sensing data. Journal of Beijing Normal University: Natural Science Edition, 2015, 51 (S1): 82- 88.
|
|
姚明煌. 2014. 随机森林及其在遥感图像分类中的应用. 厦门: 华侨大学硕士学位论文.
|
|
Yao M H. 2014. Random forest and its application in remote sensing image classification. Xiamen: MS thesis of Overseas Chinese University. [in Chinese]
|
|
钟舒怡, 李向新, 柏叶辉, 等. 基于多尺度分割与光谱特征提取建成区的方法. 软件导刊, 2018, 17 (9): 180- 184.
|
|
Zhong S Y , Li X X , Bai Y H , et al. A method for extracting built-up regions based on multiscale segmentation and spectral features. Software Guide, 2018, 17 (9): 180- 184.
|
|
朱凌红, 周澎, 王忠民, 等. 高光谱数据与叶绿素含量及植被指数的相关性研究进展. 内蒙古民族大学学报: 自然科学版, 2014, 29 (1): 41- 44.
doi: 10.3969/j.issn.1671-0185.2014.01.014
|
|
Zhu L H , Zhou P , Wang Z M , et al. Research progress on correlation of hyperspectral data with chlorophyll content and vegetation index. Journal of Inner Mongolia University for Nationalities: Natural Science Edition, 2014, 29 (1): 41- 44.
doi: 10.3969/j.issn.1671-0185.2014.01.014
|
|
Andersen H E , Mcgaughey R J , Reutebuch S E . Estimating forest canopy fuel parameters using LiDAR data. Remote Sensing of Environment, 2005, 94 (4): 441- 449.
doi: 10.1016/j.rse.2004.10.013
|
|
Asner G P , Martin R E . Canopy phylogenetic, chemical and spectral assembly in a lowland Amazonian forest. New Phytol, 2011, 189 (4): 999- 1012.
doi: 10.1111/j.1469-8137.2010.03549.x
|
|
Clément D , Clément M , Arnaud L B , et al. Semantic segmentation of forest stands of pure species combining airborne LiDAR data and very high resolution multispectral imagery. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 126, 129- 145.
|
|
Cortes C , Vapnik V . Support-vector networks. Machine Learning, 1955, 20, 273- 297.
|
|
Dash J , Curran P J . The MERIS terrestrial chlorophyll index. International Journal of Remote Sensing, 2004, 25 (23): 5003- 5013.
|
|
Lefsky M A , Cohen W B , Parker G G , et al. LiDAR remote sensing for ecosystem studies. BioScience, 2002, 52 (1): 19- 30.
doi: 10.1641/0006-3568(2002)052[0019:LRSFES]2.0.CO;2
|
|
Mountrakis M J , Ogole C . Support vector machines in remote sensing: a review. ISPRS Journal of Photogrammetry and Remote Sensing, 2011, 66 (3): 247- 259.
doi: 10.1016/j.isprsjprs.2010.11.001
|
|
Shi Y F , Andrew K S , Tiejun W , et al. Tree species classification using plant functional traits from LiDAR and hyperspectral data. International Journal of Applied Earth Observation and Geoinformation, 2018, 73, 207- 219.
doi: 10.1016/j.jag.2018.06.018
|
|
Wulder M A , Hall R J , Coops N C , et al. High spatial resolution remotely sensed data for ecosystem characterization. BioScience, 2004, 54 (6): 511- 521.
doi: 10.1641/0006-3568(2004)054[0511:HSRRSD]2.0.CO;2
|
|
Zhao Y J , Zeng Y , Zheng Z J , et al. Forest species diversity mapping using airborne LiDAR and hyperspectral data in a subtropical forest in China. Remote Sensing of Environment, 2018, 213, 104- 114.
doi: 10.1016/j.rse.2018.05.014
|