
Scientia Silvae Sinicae ›› 2021, Vol. 57 ›› Issue (3): 51-66.doi: 10.11707/j.1001-7488.20210306
Previous Articles Next Articles
Xianglin Tian1,2,Ziyan Liao3,4,Shuaichao Sun5,Hailian Xue6,Bin Wang7,Tianjian Cao1,*
Received:2019-04-29
Online:2021-03-25
Published:2021-04-07
Contact:
Tianjian Cao
CLC Number:
Xianglin Tian,Ziyan Liao,Shuaichao Sun,Hailian Xue,Bin Wang,Tianjian Cao. Impacts of Multiple Source Data on Forest Forecasting and Uncertainty Propagation[J]. Scientia Silvae Sinicae, 2021, 57(3): 51-66.

Fig.1
The locations of the sampling plots in study area The 90 m-DEM (digital elevation models) was downloaded from the CGIAR-CSI GeoPortal (http://srtm.csi.cgiar.org). The locations only include the data in and after 2012, other earlier datasets were from same compartments."

Table 1
Characteristics of the angle gauge plots used in continuously updated modelling"
| 项目Item | 1990 | 2005 | 2012 | |
| 样地数量Sample size | 58 | 68 | 45 | |
| 林分年龄Stand age/a | 最小值Min. | 15 | 25 | 30 |
| 平均值Mean | 28 | 50 | 58 | |
| 最大值Max. | 60 | 81 | 87 | |
| 林分高Stand height/m | 最小值Min. | 5.0 | 8.0 | 8.2 |
| 平均值Mean | 10.4 | 14.8 | 16.3 | |
| 最大值Max. | 16.0 | 25.0 | 21.0 | |
| 林分平均胸径Stand mean DBH/cm | 最小值Min. | 8.0 | 12.0 | 17.1 |
| 平均值Mean | 17.6 | 22.5 | 26.1 | |
| 最大值Max. | 44.0 | 33.0 | 35.4 | |
| 林分密度Stand density/(trees·hm-2) | 最小值Min. | 182 | 151 | 229 |
| 平均值Mean | 874 | 570 | 523 | |
| 最大值Max. | 2 355 | 1 557 | 1 006 | |
Table 2
Characteristics of the multiple source data used in integration modelling"
| 数据类型 Type of data | 角规临时样地 Temporary plot(TP) | 矩形固定样地 Permanent plot(PP) | 解析木 Stem analysis(SA) | |
| 调查年份Investigation year | 1990, 2005, 2012—2015 | 2012—2015 | 1980, 2003 | |
| 样地数量Sample size | 215 | 22 | 11 | |
| 林分年龄Stand age/a | 最小值Min. | 15 | 20 | |
| 平均值Mean | 46 | 35 | ||
| 最大值Max. | 87 | 68 | ||
| 林分高Stand height/m | 最小值Min. | 5.0 | 8.6 | |
| 平均值Mean | 13.4 | 12.5 | ||
| 最大值Max. | 25.0 | 20.4 | ||
| 林分平均胸径Stand mean DBH/cm | 最小值Min. | 8.0 | 12.9 | |
| 平均值Mean | 22.0 | 17.4 | ||
| 最大值Max. | 44.0 | 24.8 | ||
| 林分密度Stand density/(trees·hm-2) | 最小值Min. | 151 | 600 | |
| 平均值Mean | 628 | 1 595 | ||
| 最大值Max. | 2 355 | 3 123 | ||
Table 3
Posterior probability distribution of the parameters in continuously updated modelling"
| 参数 Parameter | 基于1990年数据的首次拟合 1990 (initial fitting) | 基于2005年数据的一次校正 2005 (calibrated once) | 基于2012年数据的二次校正 2012 (calibrated twice) | ||||||||
| 均值Mean | 标准差SD | 最大后验MAP | 均值Mean | 标准差SD | 最大后验MAP | 均值Mean | 标准差SD | 最大后验MAP | |||
| b1 | 19.145 8 | 1.164 9 | 18.311 0 | 21.358 6 | 1.087 5 | 21.114 1 | 22.445 6 | 0.612 4 | 22.830 4 | ||
| b2 | 17.457 3 | 1.595 0 | 16.910 0 | 19.310 2 | 1.678 7 | 18.914 0 | 21.752 9 | 1.114 0 | 22.417 9 | ||
| c1 | 12.188 3 | 1.819 9 | 10.221 0 | 25.654 9 | 2.046 0 | 26.918 4 | 28.301 6 | 1.267 2 | 29.871 8 | ||
| c2 | 0.323 3 | 0.063 7 | 0.387 5 | 0.039 3 | 0.031 6 | 0.019 2 | 0.027 3 | 0.019 7 | 0.004 1 | ||
| c3 | 5.252 9 | 1.366 3 | 5.404 5 | 3.590 3 | 0.578 2 | 3.672 5 | 4.862 0 | 0.475 7 | 4.774 3 | ||
| c4 | 1.371 2 | 0.196 7 | 1.291 6 | 2.375 1 | 0.169 2 | 2.397 2 | 2.205 6 | 0.105 6 | 2.215 8 | ||
| d1 | 22.197 5 | 2.126 8 | 20.666 8 | 32.189 7 | 2.675 2 | 35.328 9 | 37.048 7 | 1.665 5 | 36.943 9 | ||
| d2 | 0.156 3 | 0.057 0 | 0.163 3 | 0.033 3 | 0.029 8 | 0.003 2 | 0.017 8 | 0.016 4 | 0.015 2 | ||
| d3 | 19.043 4 | 2.854 3 | 17.468 1 | 20.178 5 | 1.697 0 | 20.260 1 | 23.997 3 | 1.410 6 | 24.213 0 | ||
| d4 | 0.057 6 | 0.045 5 | 0.010 2 | 0.028 2 | 0.026 1 | 0.002 0 | 0.092 4 | 0.048 2 | 0.160 6 | ||
Table 4
Posterior probability distribution of the parameters in the multiple source data(MSD) modelling"
| 参数 Parameter | 临时样地TP | 固定样地PP | 解析木SA | 多源数据MSD | |||||||||||
| 均值 Mean | 标准差 SD | 最大后验 MAP | 均值 Mean | 标准差 SD | 最大后验 MAP | 均值 Mean | 标准差 SD | 最大后验 MAP | 均值 Mean | 标准差 SD | 最大后验 MAP | ||||
| b1 | 22.445 6 | 0.612 4 | 22.830 4 | 20.777 6 | 1.263 4 | 19.888 2 | 29.766 9 | 0.217 6 | 29.996 2 | 22.529 9 | 0.565 0 | 22.637 6 | |||
| b2 | 21.752 9 | 1.114 0 | 22.417 9 | 17.025 6 | 1.511 7 | 16.254 4 | 20.868 3 | 0.601 0 | 21.089 8 | 20.218 4 | 0.966 3 | 20.355 2 | |||
| c1 | 28.301 6 | 1.267 2 | 29.871 8 | 21.259 3 | 5.527 1 | 29.477 4 | 28.804 5 | 1.074 6 | 29.919 6 | ||||||
| c2 | 0.027 3 | 0.019 7 | 0.004 1 | 0.206 4 | 0.117 9 | 0.087 2 | 0.023 7 | 0.016 8 | 0.000 7 | ||||||
| c3 | 4.862 0 | 0.475 7 | 4.774 3 | 9.809 2 | 2.063 2 | 11.730 7 | 5.231 8 | 0.494 9 | 4.779 6 | ||||||
| c4 | 2.205 6 | 0.105 6 | 2.215 8 | 0.583 9 | 0.533 7 | 0.285 3 | 2.111 3 | 0.104 6 | 2.205 6 | ||||||
| d1 | 37.048 7 | 1.665 5 | 36.943 9 | 23.669 3 | 2.034 8 | 21.567 1 | 36.186 8 | 1.547 0 | 35.756 8 | ||||||
| d2 | 0.017 8 | 0.016 4 | 0.015 2 | 0.052 0 | 0.032 1 | 0.068 5 | 0.015 2 | 0.014 5 | 0.019 9 | ||||||
| d3 | 23.997 3 | 1.410 6 | 24.213 0 | 13.876 3 | 1.172 4 | 12.707 9 | 22.690 0 | 1.040 9 | 23.000 6 | ||||||
| d4 | 0.092 4 | 0.048 2 | 0.160 6 | 0.070 4 | 0.061 2 | 0.049 5 | 0.070 0 | 0.037 1 | 0.090 0 | ||||||

Fig.2
The Markov Chain Monte Carlo trace plots and posterior marginal parameter probability distributions for b1"


Fig.3
The two dimensional kernel density estimation for b1 and b2 based on three periods data"


Fig.4
Violin plots of height predictions from guide curves of stand mean height at the age of 20, 40, and 60 years Violin plots are basically kernel density plots superimposed in a mirror image fashion over box plots. Here, the white dot is the median, the black boxes range from the lower to the upper quartile, and the thin black lines represent the whiskers. The outer shape provides the kernel density plots. The same below."


Fig.5
Development of stand mean height (guide curves), mean DBH and basal area (SCI=11, SDI=600) The uncertainty of predictions, 95% Bayesian credible interval, were showed in grey area. The same below."

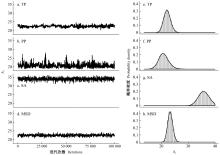
Fig.6
The Markov Chain Monte Carlo trace plots and posterior marginal parameter probability distributions for b1 TP, PP, SA, and MSD are respectively variable-radius temporary plot, rectangular permanent plot, stem analysis, and multiple source data. The same below."


Fig.7
The two dimensional kernel density estimation for b1 and b2 based on multiple source data, along with the impacts on the guide curve"


Fig.8
Violin plots of tree height predictions from guide curves of stand mean height at the age of 20, 40, and 60 years"
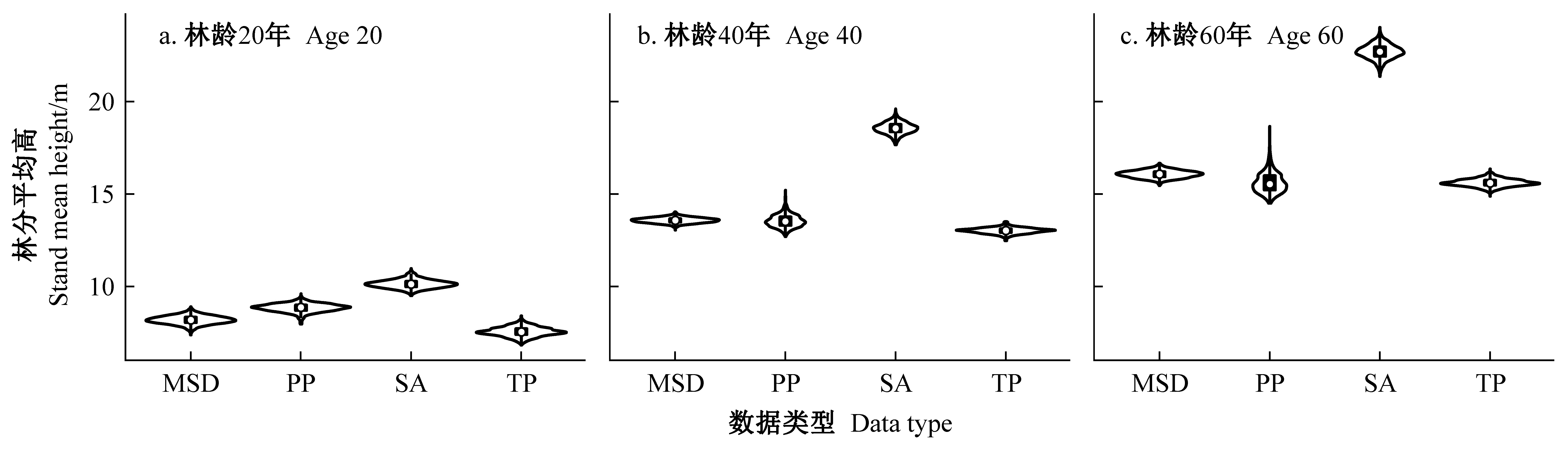

Fig.9
Development of stand mean DBH and basal area (SCI=11, SDI=600), which were updated based on multiple source data"

Table 5
Variance based uncertainty partitioning"
| 参数 Parameter | 模型参数对各输出变量的Sobol总效应指数Sobol’s total-effect indices of parameter to the output | |||
| 林分平均高 Stand mean height | 林分断面积 Stand basal area | 林分平均胸径 Stand mean DBH | 林分密度 Stand density | |
| b1 | 0.94 | — | — | — |
| b2 | 0.89 | — | — | — |
| c1 | — | 0.93 | — | 0.90 |
| c2 | — | 0.99 | — | 0.96 |
| c3 | — | 1.00 | — | 0.98 |
| c4 | — | 0.83 | — | 0.75 |
| d1 | — | — | 0.80 | 0.95 |
| d2 | — | — | 0.72 | 0.90 |
| d3 | — | — | 0.78 | 0.83 |
| d4 | — | — | 0.36 | 0.46 |

Fig.10
Uncertainty of stand basal area model simulations changes with the number of sampling plots (SCI=11, SDI=600)"

| 符利勇, 雷渊才, 孙伟, 等. 不同林分起源的相容性生物量模型构建. 生态学报, 2014, 34 (6): 1461- 1470. | |
| Fu L Y , Lei Y C , Sun W , et al. Development of compatible biomass models for trees from defferent stand origin. Acta Ecologica Sinica, 2014, 34 (6): 1461- 1470. | |
|
郭小阳, 吴恒, 田相林, 等. 基于优势高模型分析多源数据对立地质量评价的影响. 西北林学院学报, 2017, 32 (6): 184- 189.
doi: 10.3969/j.issn.1001-7461.2017.06.28 |
|
|
Guo X Y , Wu H , Tian X L , et al. Effect fo multiple source data on site evaluation based on dominant height modeling. Journal of Northwest Forest University, 2017, 32 (6): 184- 189.
doi: 10.3969/j.issn.1001-7461.2017.06.28 |
|
| 洪玲霞. 由全林整体生长模型推导林分密度控制图的方法. 林业科学研究, 1993, 6 (5): 510- 516. | |
| Hong L X . An approach to derive stand density control chart from the integrated stand growth model. Forest Research, 1993, 6 (5): 510- 516. | |
|
洪玲霞, 雷相东, 李永慈. 蒙古栎林全林整体生长模型及其应用. 林业科学研究, 2012, 25 (2): 201- 206.
doi: 10.3969/j.issn.1001-1498.2012.02.015 |
|
|
Hong L X , Lei X D , Li Y C . Integrated stand growth model of Mongolian oak and it's application. Forest Research, 2012, 25 (2): 201- 206.
doi: 10.3969/j.issn.1001-1498.2012.02.015 |
|
| 李希菲, 唐守正, 王松林. 大岗山实验局杉木人工林可变密度收获表的编制. 林业科学研究, 1988, 1 (4): 382- 389. | |
| Li X F , Tang S Z , Wang S L . The establishment of variable density yield table for Chinese fir plantation in Dagangshan experiment bureau. Forest Research, 1988, 1 (4): 382- 389. | |
| 李悦黎, 杜纪山. 火地塘教学实验林场森林资源的数据分析及经营对策. 西北林学院学报, 1993, 8 (3): 53- 58. | |
| Li Y L , Du J S . Analysis and management strategy of forest resources of Huoditang teaching and experimental forest farm. Jorunal of Northest Forestry College, 1993, 8 (3): 53- 58. | |
| 唐守正. 广西大青山马尾松全林整体生长模型及其应用. 林业科学研究, 1991, 4 (增): 8- 13. | |
| Tang S Z . Integrated stand growth model of massion pine in Daqingshan Mountain, Guangxi Province. Forest Research, 1991, 4 (Supp.): 8- 13. | |
|
唐守正. 同龄纯林自然稀疏规律的研究. 林业科学, 1993, 29 (3): 234- 241.
doi: 10.3321/j.issn:1001-7488.1993.03.005 |
|
|
Tang S Z . The research of self-thinning law for even-aged pure stands. Scientia Silvae Sinicae, 1993, 29 (3): 234- 241.
doi: 10.3321/j.issn:1001-7488.1993.03.005 |
|
|
唐守正, 杜纪山. 利用树冠竞争因子确定同龄间伐林分的断面积生长过程. 林业科学, 1999, 35 (6): 35- 41.
doi: 10.3321/j.issn:1001-7488.1999.06.005 |
|
|
Tang S Z , Du J S . Determining basal area growth process of thinned even-aged stands by crown competition factor. Scientia Silvae Sinicae, 1999, 35 (6): 35- 41.
doi: 10.3321/j.issn:1001-7488.1999.06.005 |
|
| 唐守正, 李希菲. 用全林整体模型计算林分纯生长量的方法及精度分析. 林业科学研究, 1995, 8 (5): 471- 476. | |
| Tang S Z , Li X F . Precision Analysis on growth rates estimated by integrated whole stand growth and yield model. Forest Research, 1995, 8 (5): 471- 476. | |
| 唐守正, 李勇. 一种多元非线性度量误差模型的参数估计及算法. 生物数学学报, 1996, 11 (1): 23- 27. | |
| Tang S Z , Li Y . An algorithm for estimating multivariate non-linear error-in-measure models. Journal of Biommethmatics, 1996, 11 (1): 23- 27. | |
|
唐守正, 张淑梅. 度量误差模型及其应用. 生物数学学报, 1998, 13 (2): 161- 166.
doi: 10.3969/j.issn.1001-9626.1998.02.008 |
|
|
Tang S Z , Zhang S M . Measurement error models and their applications. Journal of Biommethmatics, 1998, 13 (2): 161- 166.
doi: 10.3969/j.issn.1001-9626.1998.02.008 |
|
| 吴恒, 党坤良, 田相林, 等. 秦岭林区天然次生林与人工林立地质量评价. 林业科学, 2015, 51 (4): 78- 88. | |
| Wu H , Dang K L , Tian X L , et al. Evaluating site quality for secondary forests and plantation in Qinling Mountains. Scientia Silvae Sinicae, 2015, 51 (4): 78- 88. | |
| 张少昂. 兴安落叶松天然林林分生长模型和可变密度收获表的研究. 东北林业大学学报, 1986, 14 (3): 17- 25. | |
| Zhang S A . Study on natural Dahurian larch stand growth model and variable density yield table. Journal of Northeast Forestry University, 1986, 14 (3): 17- 25. | |
| 张雄清, 张建国, 段爱国. 基于贝叶斯法估计杉木人工林树高生长模型. 林业科学, 2014, 50 (3): 69- 75. | |
| Zhang X Q , Zhang J G , Duan A G . Tree-height growth model for Chinese fir plantation based on Bayesian method. Scientia Sivae Sinicae, 2014, 50 (3): 69- 75. | |
| Ando T , Zellner A . Hierarchical Bayesian analysis of the seemingly unrelated regression and simultaneous equations models using a combination of direct Monte Carlo and importance sampling techniques. Bayesian Analysis, 2010, 5 (1): 65- 95. | |
| Berger J O . Bayesian analysis: a look at today and thoughts of tomorrow. Journal of the American Statistical Association, 2000, 95 (452): 1269- 1276. | |
| Bijleveld C C J H , van der Kamp L J T . Longitudinal data analysis: designs, models and methods. SAGE Publications Ltd, 1998. | |
| Bontemps J D , Hervé J C , Dhôte J F . Long-tern changes in forest productivity: a consistent assessment in even-aged stands. Forest Science, 2009, 55 (6): 549- 564. | |
| Brooks S , Gelman A . General methods for monitoring convergence of iterative simulations. Journal of Computational and Graphical Statistics, 1998, 7, 434- 455. | |
| Bullock B P , Boone E L . Deriving tree diameter distributions using Bayesian model averaging. Forest Ecology and Management, 2007, 242 (2): 127- 132. | |
| Cariboni J , Gatelli D , Liska R , et al. The role of sensitivity analysis in ecological Modelling. Ecological Modelling, 2007, 203 (1/2): 167- 182. | |
| Clark J S . Models for ecological data: an introduction. New Jersey: Princeton University Press, 2007. | |
|
Clark J S , Wolosin M , Dietze M , et al. Tree growth inference and prediction from diameter censuses and ring widths. Ecological Applications, 2007, 17 (7): 1942- 1953.
doi: 10.1890/06-1039.1 |
|
| Dietze M C . Ecological forecasting. Princeton University Press, 2017. | |
|
Dietze M C , Wolosin M S , Clark J S . Capturing diversity and interspecific variability in allometries: a hierarchical approach. Forest Ecology and Management, 2008, 256 (11): 1939- 1948.
doi: 10.1016/j.foreco.2008.07.034 |
|
|
Efron B . Computers and the theory of statistics: thinking the unthinkable. SIAM Review, 1979, 21 (4): 460- 480.
doi: 10.1137/1021092 |
|
| Fox T R . Sustained productivity in intensively managed forest plantations. Forest Ecology and Management, 2000, 138 (1/3): 187- 202. | |
|
Gelfand A E , Smith A F . Sampling-based approaches to calculating marginal densities. Journal of the American statistical association, 1990, 85 (410): 398- 409.
doi: 10.1080/01621459.1990.10476213 |
|
| Gelman A , Hill J . Data analysis using regression and multilevel/hierarchical models. Cambridge University Press, 2007. | |
| Gelman A, Rubin D. 1992. Inference from iterative simulation using multiple sequences. Technical Report No. 307. vol 7. | |
| Gilks W R , Richardson S , Spiegelhalter D J . Markov Chain Monte Carlo in practice. London: Chapman and Hall, 1996. | |
| Green E J , Strawderman W E . A Bayesian growth and yield model for slash pine plantations. Journal of Applied Statistics, 1996, 23 (2/3): 285- 300. | |
| Hann D L, Hanus M. 2002. Enhanced diameter-growth-rate equations for undamaged and damaged trees in southwest Oregon. Research Contribution 39. Oregon State University, Forest Research Laboratory, Corvallis O R. | |
|
Hartig F , Dyke J , Hickler T , et al. Connecting dynamic vegetation models to data-an inverse perspective. Journal of Biogeography, 2012, 39 (12): 2240- 2252.
doi: 10.1111/j.1365-2699.2012.02745.x |
|
| Hartig F, Minunno F, Paul S. 2019. BayesianTools: general-purpose MCMC and SMC samplers and tools for Bayesian statistics. R package version 0. 1. 7. https://CRAN.R-project.org/package=BayesianTools. | |
|
Hastings W K . Monte Carlo sampling methods using Markov chains and their applications. Biometrika, 1970, 57 (1): 97- 109.
doi: 10.1093/biomet/57.1.97 |
|
| Iooss B, Da Veiga S, Janon A, et al. 2020. sensitivity: Global Sensitivity Analysis of Model Outputs. R package version 1. 19. 0. https://CRAN.R-project.org/package=sensitivity. | |
| Kangas A , Maltamo M . Forest inventory: methodology and applications. Netherlands: Springer Science & Business Media, 2006. | |
|
LeBauer D S , Wang D , Richter K T , et al. Facilitating feedbacks between field measurements and ecosystem models. Ecological Monographs, 2013, 83 (2): 133- 154.
doi: 10.1890/12-0137.1 |
|
| Li R , Stewart B , Weiskittel A . A Bayesian approach for modelling non-linear longitudinal/hierarchical data with random effects in forestry. Forestry, 2011, 85 (1): 17- 25. | |
|
Marler R T , Arora J S . The weighted sum method for multi-objective optimization: new insights. Structural Multidisciplinary Optimization, 2010, 41 (6): 853- 862.
doi: 10.1007/s00158-009-0460-7 |
|
|
Metcalf C J E , McMahon S M , Clark J S . Overcoming data sparseness and parametric constraints in modeling of tree mortality: a new nonparametric Bayesian model. Canadian Journal of Forest Research, 2009, 39 (9): 1677- 1687.
doi: 10.1139/X09-083 |
|
|
Metropolis N , Rosenbluth A W , Rosenbluth M N , et al. Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 1953, 21 (6): 1087- 1092.
doi: 10.1063/1.1699114 |
|
| Monserud R A , Rehfeldt G E . Genetic and environmental components of variation of site index in inland Douglas-fir. Forest Science, 1990, 36 (1): 1- 9. | |
| Pretzsch H . Forest dynamics, growth, and yield. Heidelberg: Springer, 2010. | |
| Radtke P J , Robinson A P . A Bayesian strategy for combining predictions from empirical and process-based models. Ecological Modelling, 2006, 190 (3): 287- 298. | |
| Raulier F , Lambert M C , Pothier D , et al. Impact of dominant tree dynamics on site index curves. Forest Ecology and Management, 2003, 184 (1/3): 65- 78. | |
| Reineke L H . Perfecting a stand-density index for even-aged forests. Journal of Agricultural Research, 1933, 46 (7): 627- 638. | |
| Saltelli A , Ratto M , Andres T , et al. Global sensitivity analysis: the primer. John Wiley & Sons, 2008, | |
| Schroth G , Sinclair F . Trees, crops and soil fertility-concepts and research methods. Wallingford: CABI pubishing, 2003. | |
| Schumacher F . A new growth curve and its application to timber yield studies. Journal of Forestry, 1939, 37 (33): 819- 820. | |
| Sivia D , Skilling J . Data analysis: a Bayesian tutorial. UK: Oxford University Press, 2006. | |
|
Skovsgaard J P , Vanclay J K . Forest site productivity: a review of the evolution of dendrometric concepts for even-aged stands. Forestry, 2008, 81 (1): 13- 31.
doi: 10.1093/forestry/cpm041 |
|
| Van Laar A , Akça A . Forest mensuration. Netherlands: Springer Science & Business Media, 2007. | |
|
Van Oijen M . Bayesian methods for quantifying and reducing uncertainty and error in forest models. Current Forestry Reports, 2017, 3 (4): 269- 280.
doi: 10.1007/s40725-017-0069-9 |
|
|
Van Oijen M , Rougier J , Smith R . Bayesian calibration of process-based forest models: bridging the gap between models and data. Tree Physiology, 2005, 25 (7): 915- 927.
doi: 10.1093/treephys/25.7.915 |
|
| Ware J , Liang K . The design and analysis of longitudinal studies: a historical perspective. Advances in Biometry, 1996, 339- 362. | |
| Weiskittel A R , Hann D W , Kershaw Jr J A , et al. Forest growth and yield modeling. John Wiley & Sons, 2011, | |
| West M , Harrison J . Bayesian forecasting and dynamic models. New York: Springer, 1997. | |
|
Zapata-Cuartas M , Sierra C A , Alleman L . Probability distribution of allometric coefficients and Bayesian estimation of aboveground tree biomass. Forest Ecology and Management, 2012, 277, 173- 179.
doi: 10.1016/j.foreco.2012.04.030 |
|
|
Zhang X , Duan A , Zhang J . Tree biomass estimation of Chinese fir (Cunninghamia lanceolata) based on bayesian method. PloS One, 2013, 8 (11): e79868..
doi: 10.1371/journal.pone.0079868 |
|
|
Zellner A . An efficient method of estimating seemingly unrelated regressions and tests for aggregation bias. Journal of the American statistical Association, 1962, 57 (298): 348- 368.
doi: 10.1080/01621459.1962.10480664 |
| [1] | Bin Wang,Xianglin Tian,Tianjian Cao. Uncertainty Analysis of Height Predictions for Young Pinus tabulaeformis Using a Bayesian Approach [J]. Scientia Silvae Sinicae, 2020, 56(11): 73-86. |
| [2] | Xiao He,Yuancai Lei,Chunquan Xue,Qihu Xu,Haikui Li,Lei Cao. Carbon Density Uncertainty Estimates for Schima superba in Guangdong Province [J]. Scientia Silvae Sinicae, 2019, 55(11): 163-171. |
| [3] | Ren Chong, Ju Hongbo, Zhang Huaiqing, Huang Jianwen, Zheng Yingxuan. Multi-Source Data for Forest Land Type Precise Classification [J]. Scientia Silvae Sinicae, 2016, 52(6): 54-65. |
| [4] | Zu Xiaofeng, Li Qiushi, Ni Chengcai, Qin Xianlin, Nigh Gorden. Analysis and Comparison of Combinations among Fitting NLME and Predictors of Random Parameters and Response Variables [J]. Scientia Silvae Sinicae, 2016, 52(10): 72-79. |
| [5] | Qin Jianhua;Stephen J.Titus;Shongming Huang. TEH STUDY SYNTHESIS OF STAND GROWTH AND YIELD MODEL SYSTEMS [J]. Scientia Silvae Sinicae, 2002, 38(1): 122-129. |
| [6] | Jiang Yiyin;Li fengri. A STUDY ON THE GROWTH AND YIELD OF NATURAL DAHURIAN LARCH STANDS [J]. , 1989, 25(5): 477-482. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||